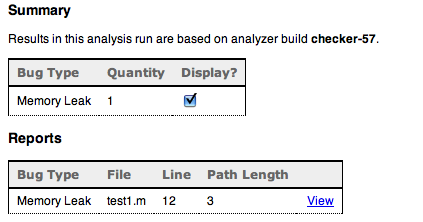
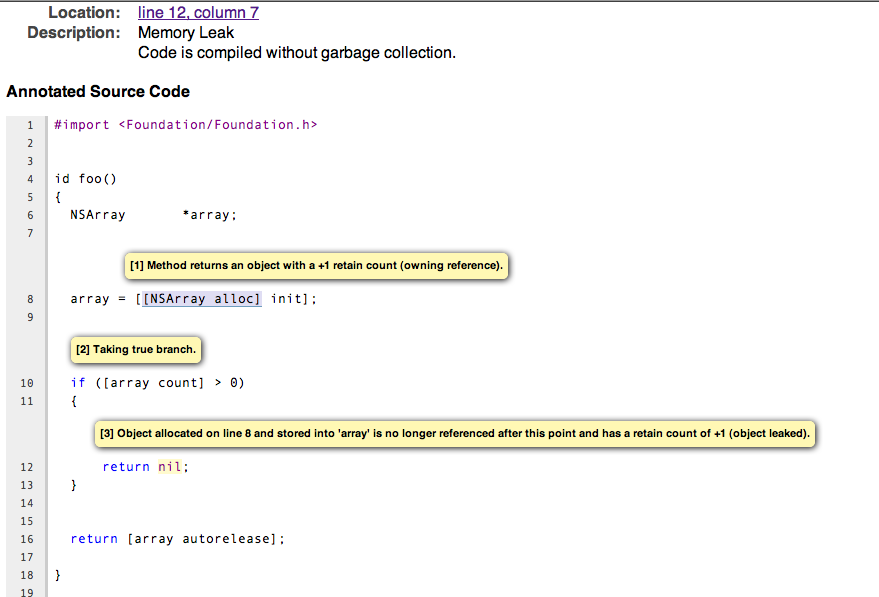
Codesigning & Notarization Woes
As mentioned in my last post, I had various issues with codesigning and notarization during Hazel 5’s launch. Now before I get into it, remember during all this that Hazel is codesigned and notarized with no warnings or errors. In my release build process, I do a codesign —verify as well as spctl to make sure everything is hunky-dory before submitting to Apple for notarization.
The biggest problem at launch was some users getting an “Unidentified developer” alert when opening the dmg. I had various users send in logs, but it was only when someone found a log message pertaining to the rpath for one of the binaries in the bundle that I was able to identify the problem. Strangely enough, that person didn’t receive the “Unidentified developer” error alert.
Turns out, I had mistakenly added a binary to the top level bundle (it was originally in a framework). The binary had an rpath which escaped the framework bundle as it depended on a sibling framework. This worked fine when the binary was in the framework bundle but when it was at the top level of the main app bundle, it escaped the app bundle itself. Not sure how the binary got added to the Copy Files phase there but it was an easy fix to remove.
Another issue was that the installer wasn’t triggering for some people. For the installer to trigger, Hazel needs to detect that it is running from a disk image. Further investigation turned up that Hazel was being translocated. If you don’t know what translocation is, I suggest reading this article: https://lapcatsoftware.com/articles/app-translocation.html
When translocated, the binary is no longer on the disk image, instead it is copied to a temp location on disk. Hazel is unaware of this and as a result, doesn’t run the installer. Why was Hazel being translocated? I’m still not sure. It’s my understanding that if an app and its containing dmg is signed and notarized, it shouldn’t be translocated. As a workaround, I ended up using the private SecTranslocate.h APIs to detect the translocation and compensate appropriately.
Possibly related to the above, there was also an issue with the embedded helper app not running. Logs from users showed that the quarantine flag was still set on the helper and that was preventing it from being run. When the user copies an app, like say from a disk image to /Applications, the quarantine flag should be cleared for the app and everything inside but for some reason it was not clearing it for the embedded binaries. Note that unlike when a user launches an app from Finder where they will be asked to run the app, a login item helper will fail to launch without any prompt. As a short term workaround, on first run, I had Hazel recursively remove its quarantine flag before it attempted to run the helper.
Even with the workarounds, something didn’t sit right with me. I suspected there was something wrong with my bundle that was causing these issues. I ended up filing a DTS incident to get some feedback from Apple. The DTS engineer was able to reproduce the issue on a VM and dig up a log message indicating that it could not clear the quarantine flag on the Autoupdate helper app in the Sparkle framework. For those that don’t know, Sparkle is a very commonly used framework for apps to update themselves. The Autoupdate helper runs when your app is terminated so that it can install and run the new version.
This all lead to an investigation into where should Autoupdate, or executable binaries in general, be put in a framework. Now, I had looked into this once before . Sparkle originally put Autoupdate in Resources which is incorrect and can cause subtle issues. The solution I came up with back then was to put any executables alongside the framework binary, which would be in Versions/A with a symbolic link at the top level of the framework bundle. This seemed to work at the time. It got through codesigning and notarization checks without issue and ran fine after that.
But it seems that the problem is more subtle than that as whatever code that clears quarantine flags on embedded bundles didn’t like that. I was pointed to this article which suggests I put the program in Contents/Helpers. Despite the insistence that this was the way to do it, it flat out did not work. An important thing to note is that framework bundles do not have a Contents directory. Putting a Contents directory, either in Versions/A or at the top level will make codesign barf, complaining about an invalid bundle format. My guess is that when codesign sees a Contents directory, it considers the bundle to be another (non-framework) type of bundle. After wasting a good bit of time on this, I went with what I thought made more sense, putting it in a Helpers directory (sans Contents). If you have an Xcode “Copy Files” phase copy to Resources for a framework, for instance, it doesn’t put it in Contents/Resources, but in Resources so it made some sense to do it this way.
Sure enough, that worked. Of course, after fixing it, someone pointed out how some of the system frameworks use the Helper directory. I guess I should’ve checked there first. At least I have some confirmation that I was on the right track. Note that you should put the Helper directory under Versions/A. You can symlink to the top level but that’s optional. I did it mainly to give myself a more consistent path to access it in the very unlikely event that I end up shipping different versions of the framework.
Overall, this experience has been very frustrating. There is little to no documentation on all the various things that can go wrong in your bundle that will cause things to fail, and when it does fail, the logging is very inconsistent. Lastly, none of the tools or processes in place (codesign, spctl, notarization) catch these cases. These are all issues related to the static structure of the app bundle so it seems like they should be detectable. Having a tool that developers can run on their bundles before submitting them would be very helpful as the current ones are far from complete in that regard.
After all this, I’m still not sure if the translocation problem is still there or not. I’m not about to remove a workaround just to have it fail for users just so I can get some feedback so that question will remain unanswered for the time being. The lack of definitive and correct information during this whole ordeal is a bit disturbing and makes me think that there’s no one that actually knows for sure how things really work.
For those at Fruit Company, I’ve filed FBAs FB8981011 and FB8981016.