The Bundle Blame Game
macOS Catalina introduced extra privacy protections where the user can control what apps can or cannot do. Key to this is providing the user with a correct identification of the app in question.
For many apps, this is straightforward. If the “Foo” executable, which is located in …Foo.app/Contents/MacOS, does something that requires permission, the system knows to present Foo.app as the responsible bundle. For many apps, though, it’s slightly less straightforward. There may be multiple executables in the app bundle. Nonetheless, it shouldn’t be much of a problem figuring out the responsible app bundle but for some reason, a consistent solution has eluded Apple.
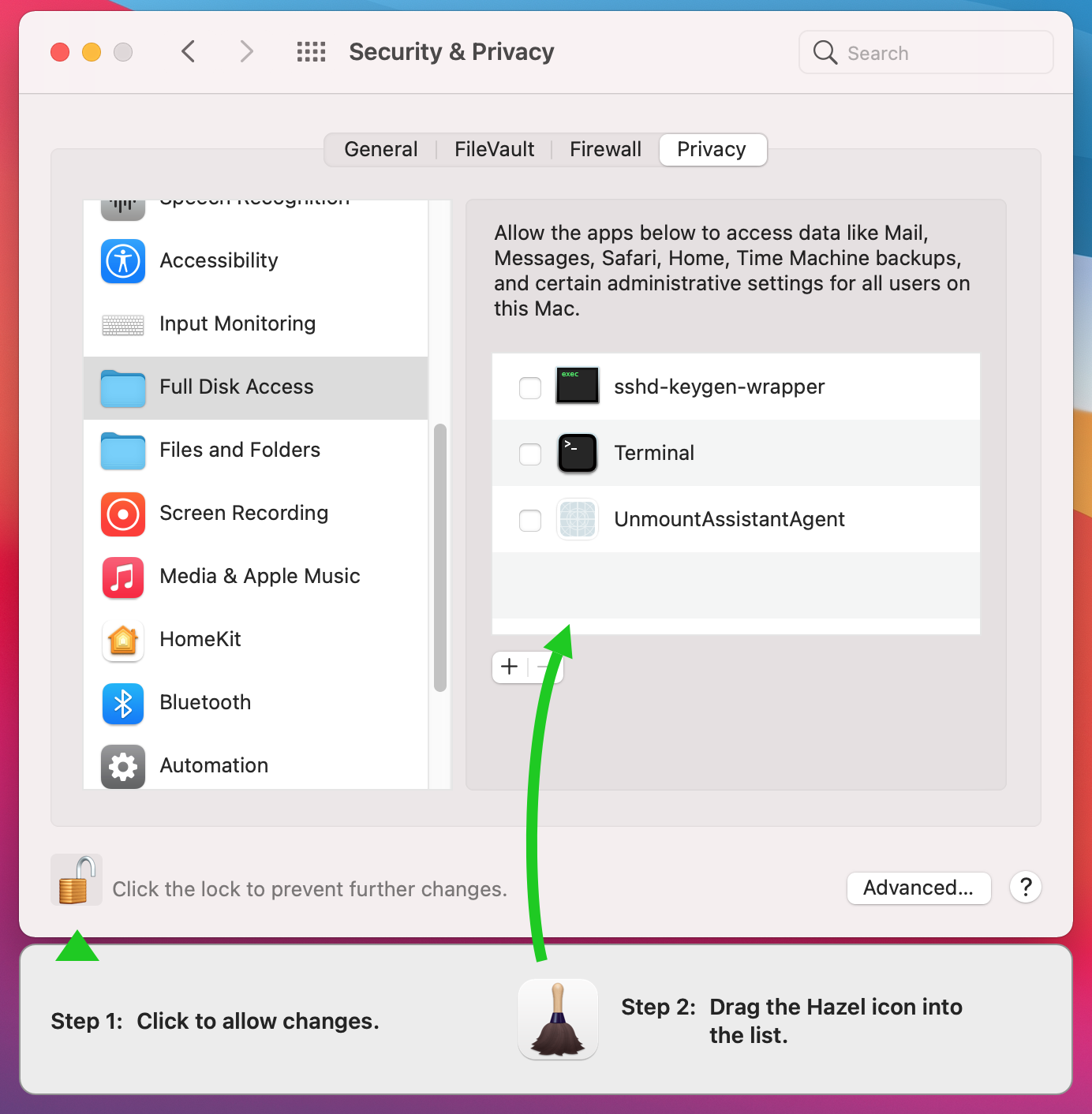
One of the main permissions that Hazel may require is Full Disk Access. If you go to that section in System Preferences/Settings, you’ll see a list of apps. You think adding and enabling your app there is all that is needed; that it should handle permissions for that app and all its subsidiary executables in its bundle. Here’s how it normally looks for Hazel.

But sometimes things go awry. All of sudden, the system requires separate permissions for the other executables in your bundle. Users will find the app not working properly and they won’t think to look at the permissions again as they thought they already given the proper permissions. Another trip to the privacy settings may show it listing the helper executables there.

Now, what the hell is that godforsaken app name? Well, it’s the team id followed by the bundle id. Unfortunately, Apple requires the crazy naming scheme for apps that are login items bundled in the main app. Is this something the user really needs to be exposed to? Minimally, Apple should observe the display name specified by the bundle but in the ultimately, this should not appear there at all.
The user should not have to understand the different running components internal to an app. This is a level of “transparency” that muddles the issue and adds nothing of value. Does the user really need to know that “Foo Helper” exists and want to really control that separately from the main app? I know for a fact that the vast majority of Hazel users have no idea how the different executables in Hazel work and interact with each other. I would not expet them to be able to judge whether it’s a good idea to give permissions to one, but not the other.
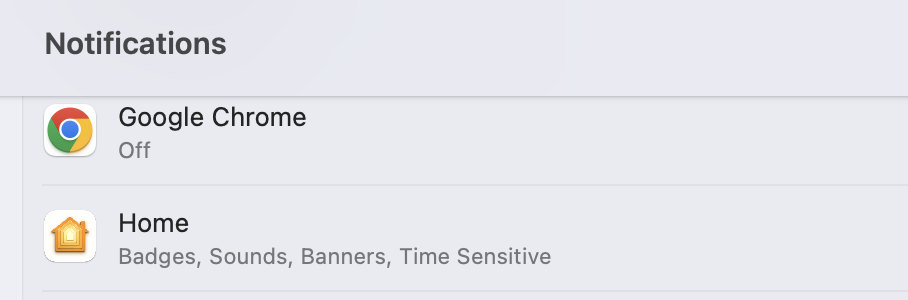
At the other end of the spectrum, other parts of the system sometimes fail to list an app at all. For instance, Hazel sends notifications via a commandline program in one of the standard locations within the bundle. With Monterey, while Hazel was properly being recognized as the responsible app in the Notification settings, it would be absent in the list of app you choose for the Focus feature. This was remedied in a Monterey point release with Hazel properly listed in both places there.
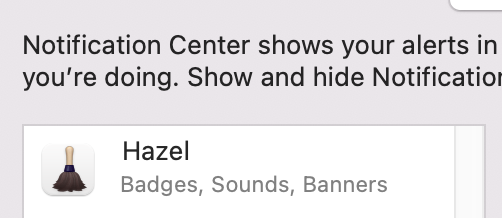
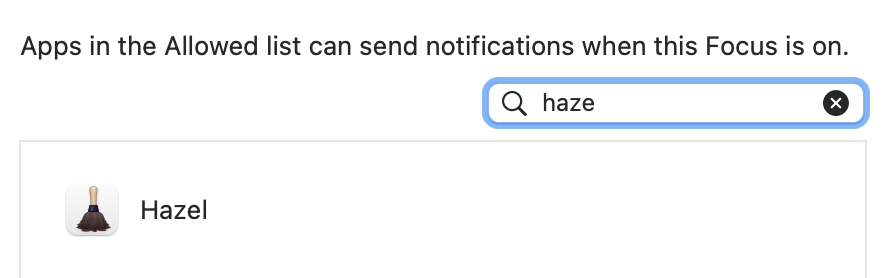
Unfortunately, Ventura broke it again and now it’s absent from both locations .
This all seems to indicate that each team working on these different bits are re-inventing the same wheel over and over and doing it incorrectly in different ways. You’d think it would be in their best interest of have someone write the canonical algorithm for this and use it across all these subsystems.
Unfortunately, for me, this has resulted in various DTS incidents and bug reports in recent years. As of this writing, it’s still a problem in Ventura (last checked on the release candidate). Apple, please get this sorted. FB11462910 (which also mentions several other related FBs) for those working at Fruit Company.
There is an unrelated major issue which I am hoping has been worked around in the current Hazel beta. If you are interested in testing, please see the forum article here (forum login required).
For the moment, if Hazel is an important part of your work, I suggest holding off on upgrading to Ventura. I’ll keep you posted on the status of these bugs via Twitter.