DevonThink & ScanSnap with Hazel. Rule & Script problem
So I am using Hazel in order to move scanned and ocr'ed PDF documents into a specific database within Devonthink. But there is a major flaw and I really don't know how to overcome it.
After scanning has finished, the PDF is placed in the folder watched by Hazel. In the meantime the OCR process begins using SnapScan's own "Searchable PDF Converter", but the process can not be completed since Hazel has moved the unfinished PDF to Devonthink. I know that I can set up additional static time rules in Hazel ("move the file after xx seconds/minutes"). But scanning time depends on how many documents have to be proceeded. Therefore it might work well for documents with few pages, but what about a stack of 30 pages in one session?
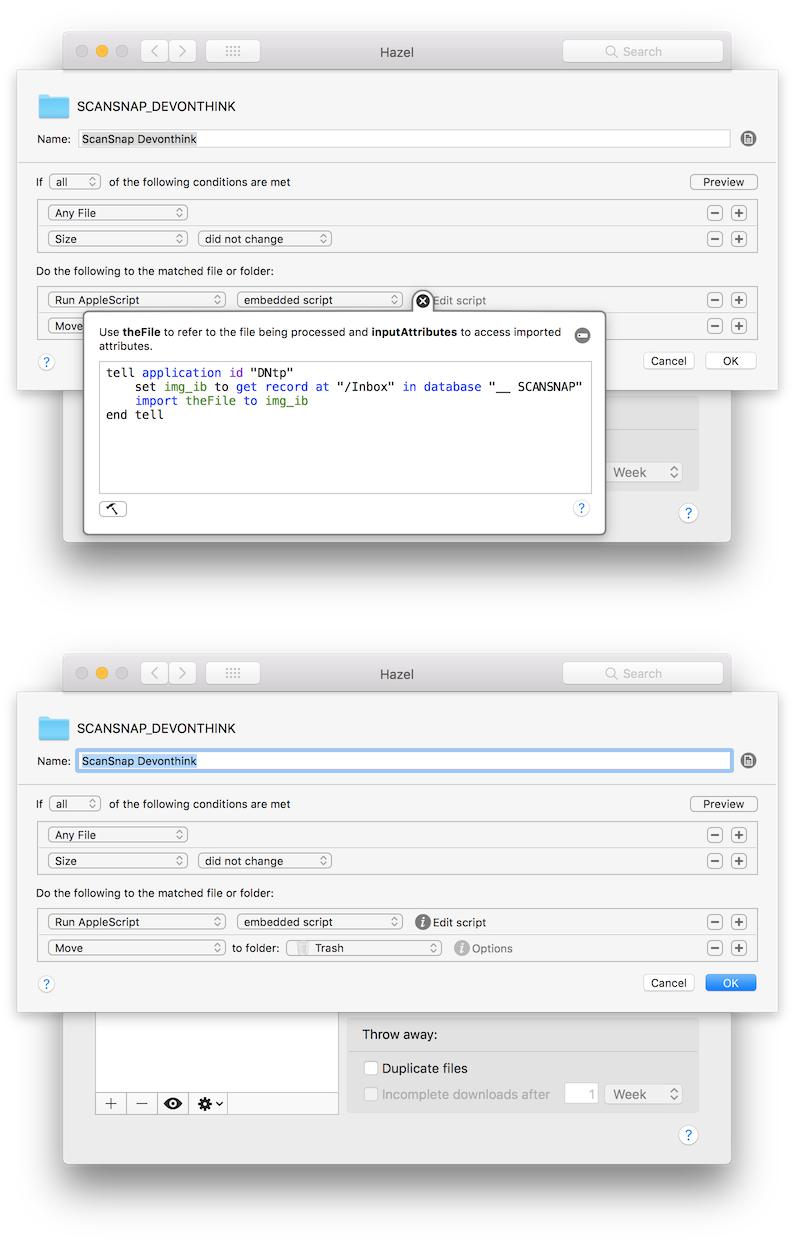
Have a look on my rules and script so far.
The AppleScript for Devonthink tells to import the file in the inbox of database "__ SCANSNAP"
My suggestions:
Additional code in order to prevent any import to Devonthink until the OCR process by the ScanSnap app called "SearchablePDFConverter" is done. However, I am NOT a script pro
After scanning has finished, the PDF is placed in the folder watched by Hazel. In the meantime the OCR process begins using SnapScan's own "Searchable PDF Converter", but the process can not be completed since Hazel has moved the unfinished PDF to Devonthink. I know that I can set up additional static time rules in Hazel ("move the file after xx seconds/minutes"). But scanning time depends on how many documents have to be proceeded. Therefore it might work well for documents with few pages, but what about a stack of 30 pages in one session?
Have a look on my rules and script so far.
The AppleScript for Devonthink tells to import the file in the inbox of database "__ SCANSNAP"
- Code: Select all
tell application id "DNtp"
set img_ib to get record at "/Inbox" in database "__ SCANSNAP"
import theFile to img_ib
end tell
My suggestions:
Additional code in order to prevent any import to Devonthink until the OCR process by the ScanSnap app called "SearchablePDFConverter" is done. However, I am NOT a script pro