Hazel "beginner", OCR, Finereader and the like
Hi...
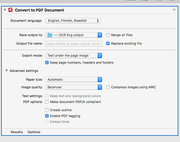
Well I am very slowly getting Hazel to do basic file manipulation for me. One of my challenges, to which I then though Hazel can help, is with the Abbyy Finereader OCR program.
Essentially I want to feed my beefy desktop machine with a lot of PDFs and have it make nice OCR versions and spit them out into a given directory. The Abbyy Automator scripts don't work if you dump 20 files into a directory -- unless you want one super-file of 20 PDFs together. I tried a "dispense" workflow routine but struggle to get it to work.
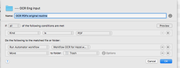
I wondered therefore Hazel. I know I am not yet ready to figure out deeper conditions, so had even wondered if a "what's the latest file" out of 20, process that, remove from the directory and loop back (what's the latest from 19, what's the latest from 18 and so on).
I've looked at these threads but am struggling to see how to put everything together.
viewtopic.php?f=4&t=7865&p=22371&hilit=finereader#p22371
viewtopic.php?f=4&t=4704&p=24942&hilit=finereader#p24942
The TL:DR, if anyone is kind enough to give some specific guidance:
I would have a specific "to process" directory
I would have a specific "processed" directory
The original files can be deleted. I would have copied them from another location anyway and would manually replace them for various reasons with the OCRed version anyway.
Standard Abbyy features (English, make into OCR).
All non-standard stuff (rotate, other languages, etc) I would run manually.
The reason for making everything OCRed is to make reading easier (visually handicapped), but in wanting to make my life easier, I have to first use the limited visual resources to struggle with an unfamiliar way of thinking (the app/programming) to do it. The bits Ihave learned have been very great and appreciated, but it is a very steep curve for me.
Thanks in advance for any pointers.
Well I am very slowly getting Hazel to do basic file manipulation for me. One of my challenges, to which I then though Hazel can help, is with the Abbyy Finereader OCR program.
Essentially I want to feed my beefy desktop machine with a lot of PDFs and have it make nice OCR versions and spit them out into a given directory. The Abbyy Automator scripts don't work if you dump 20 files into a directory -- unless you want one super-file of 20 PDFs together. I tried a "dispense" workflow routine but struggle to get it to work.
I wondered therefore Hazel. I know I am not yet ready to figure out deeper conditions, so had even wondered if a "what's the latest file" out of 20, process that, remove from the directory and loop back (what's the latest from 19, what's the latest from 18 and so on).
I've looked at these threads but am struggling to see how to put everything together.
viewtopic.php?f=4&t=7865&p=22371&hilit=finereader#p22371
viewtopic.php?f=4&t=4704&p=24942&hilit=finereader#p24942
The TL:DR, if anyone is kind enough to give some specific guidance:
I would have a specific "to process" directory
I would have a specific "processed" directory
The original files can be deleted. I would have copied them from another location anyway and would manually replace them for various reasons with the OCRed version anyway.
Standard Abbyy features (English, make into OCR).
All non-standard stuff (rotate, other languages, etc) I would run manually.
The reason for making everything OCRed is to make reading easier (visually handicapped), but in wanting to make my life easier, I have to first use the limited visual resources to struggle with an unfamiliar way of thinking (the app/programming) to do it. The bits Ihave learned have been very great and appreciated, but it is a very steep curve for me.
Thanks in advance for any pointers.